
Is Fortran "a dead language"?
Some C++ folk seem to think so...

Introduction
A recent tweet contained the phrase “dead languages such as Fortran”, which (although perhaps intended in jest) seemed worth debunking, since it is important that people making funding decisions about investments in compilers do not ignore Fortran as “a legacy language”, or even, as above, a “dead language”, since in its home domain Fortran remains critically important.
Why do People Think Fortran is Dead?
There are a few reasons for this misconception:-
Most programmers are never taught Fortran, and it is not a computer science or web language.
Fortran is only the 15th most popular language on the Tiobe index for September 2022, and is low down in IEEE’s language popularity estimates as well.
It was released in 1957 (as, indeed, was I), so, since old people know nothing, and anything from the last century is technically suspect, it clearly must be dying.
Teaching and Insularity
The issue here is really one of insularity. The web sites and teaching resources that people use depend on the jobs they have and the tasks they are trying to solve. So, one would not expect accountants to be experts in structural mechanics, or to know how to drive a fork-lift truck. We are taught the tools we need for the things we are expected to do, and are interested in.
Thus, people studying hard sciences such as physics and chemistry are taught to program in Fortran, whereas more general programmers (who, if the language popularity indices are to be believed will likely be developing web applications) are not, since Fortran is not used in that domain.
One particular group for whom this matters is the people writing the compilers. Since most compilers are now written in C or C++ (e.g. the Gnu Compiler Collection (GCC): 62.6% C++ or C, LLVM: 84% C++ or C 1), those are the languages which the compiler writers use every day, so tend to consider as "real" languages. In particular, if they improve those compilers they experience the benefits themselves.
Also, since they are not interested in Fortran, many people do not track the status of current Fortran, (which continues to evolve through Fortran 2018, with Fortran 2023 expected next year), but are under the impression that nothing has happened since Fortran 77 (or, at the latest, Fortran 90). While it is still possible to compile code in fixed, punch-card, format, modern Fortran is a more friendly language with useful built-in features for high-performance computing [HPC] codes (such as operations on whole arrays without needing to write a loop, explicitly parallel loops [do concurrent], and support for Partitioned Global Address Space [PGAS] parallelism via coarrays).
Programming Popularity Indices
It is certainly true that Fortran is low down on the programming popularity indices, but they are not measuring anything that gives us useful information about the importance of a language, but rather they tell us how many people ask questions about it (TIOBE2), or how many people are programming in it (IEEE : “we look at nine metrics that we think are good proxies for measuring what languages people are programming in.”)
However, these measures of popularity miss the point that the number of people writing in a language is a completely separate issue from how important the code is, and how much compute resource it may consume.
Consider the Vienna Ab initio Simulation Package [VASP], which is the code that consumes the most resources on the UK’s largest HPC machine (Archer2), and which is written in Fortran. At the VASP site we can see photos of the VASP team which consists of … 15 people. Clearly 15 people writing Fortran make no impact on the statistics measured by the popularity indices, yet, as we will see below, their code is hugely important.
“Legacy” bias
For reasons I cannot understand, “legacy” has become an insult, despite most of our knowledge being a legacy from previous generations. (I don’t see physicists tearing up energy conservation because it wasn’t theorised in this generation, actors complaining about having to learn a part in a Shakespeare play, or musicians complaining about playing Mozart, Bach, Beethoven, or Hildegard of Bingen who died in 1169!).
The fact that there are many well tested Fortran codes which are being used and maintained, rather than being thrown away to be replaced by expensive, new, untested code in the language du jour is a good thing, not a bad one.
While you might argue that the weather forecasts you get are bad, the forecasts save lives and many are written in Fortran (e.g. the US’ WRF, the UK Meteorological Office’s Unified Model [UM], and ECMWF’s Integrated Forecast System [IFS]).
Although Fortran may not be useful to hard-core computer-science folk, it remains one of the most important languages for scientists who are looking for a well understood, performant, portable, language in which to write the codes they need to support their real objectives of advancing knowledge in their field.
As we all know, hardware continues to advance (despite the impact of the end of Dennard scaling), but having a well understood tool that we can continue to use is important. If we buy a cross-head screwdriver we don’t throw away the straight, single slot, one we already owned, even though both are screwdrivers, rather we recognise that we need both in our toolbox. Similarly throwing away Fortran codes makes no sense. Fortran is also under continuing development, it’s just not visible to the people who make a lot of noise about the state of the C++ standard3!
With the addition of OpenMP®, Fortran codes can be extended in a vendor neutral way to operate on machines with both CPUs and GPUs or other accelerators.
“Follow the Money”
Many people (including some people writing code themselves, who, if they are logical won’t expect to be paid) think that software, and, in particular, compilers, should all be free. However, in the real world, someone has to pay the developers (glassdoor reckons the mean C++ developer salary in the US is $94,466 /yr in September 2022, which means that the cost of employing a C++ developer is likely around $150k/yr after allowing for office space, machines, travel expenses, and so on). Of course that means that the people paying the developers must be able to see significant value in the code they produce even if it is given away, since we live in a capitalist economic system, and they want to make a profit.
The compilers used in High Performance Computing [HPC] are mostly written by the providers of the hardware, and, normally, that means the designers of the CPU (or GPU) chips.
There are good reasons for this:-
To have compilers ready when a new chip comes out work has to start before the specifications are public, so an unrelated software company cannot do it.
If they are sane, the hardware architects should be worrying whether their wonderful new features can be used by compilers, so they need to be talking to compiler writers and accepting their feedback even before the specification of new instructions is finalised.
Since the price at which a CPU or GPU can be sold is related to its performance, having a compiler which improves the performance of whatever benchmark codes are used for this evaluation is valuable as it allows you to charge more for each machine you sell. Indeed, this may be a simpler, cheaper, way to achieve performance than using an improved process to make the chip, or having it run at a higher clock frequency (and thus consume more power).
Having an in-house compiler-team allows rapid fixes to be made if there are problems when running the benchmarks required for specific procurements.
To compete in a specific market the customers there must be able to run their codes on the machine you are trying to sell. In the HPC market that means having good Fortran support4.
That final reason should make it obvious why the number of programmers using a language is not the right metric for the people funding compiler development to use. Since they aren’t selling the compiler and charging people a license for each user, the number of people who will use the compiler is irrelevant. What matters is how much hardware is needed to run code that requires support for the language the compiler supports.
Some Real Numbers
Luckily for us, the Edinburgh Parallel Computing Centre (EPCC) who run Archer2 (which is the largest centrally funded machine for scientific research here in the UK and is 25th in the June 2022 Top500 list of supercomputers) publish information on the applications which are being run on the machine5.
Although they don’t currently publish information about the language in which each application is written, a morning on Google and a few emails to code authors let me fill in that information for most of the codes. The EPCC statistics do have a large chunk of “Unidentified” codes; we’ll discuss how usefully to allocate these to a programming language below.
Looking at the statistics for the last six months (March-August 2022), there are 43 applications which use more than 0.1% of the machine; those which use more than 1% of the machine (as identified by the program name in the statistics) are
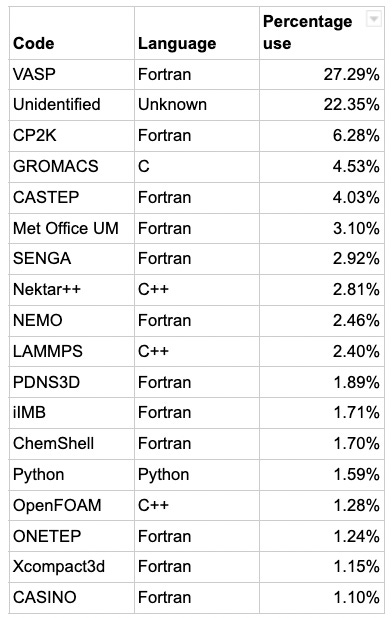
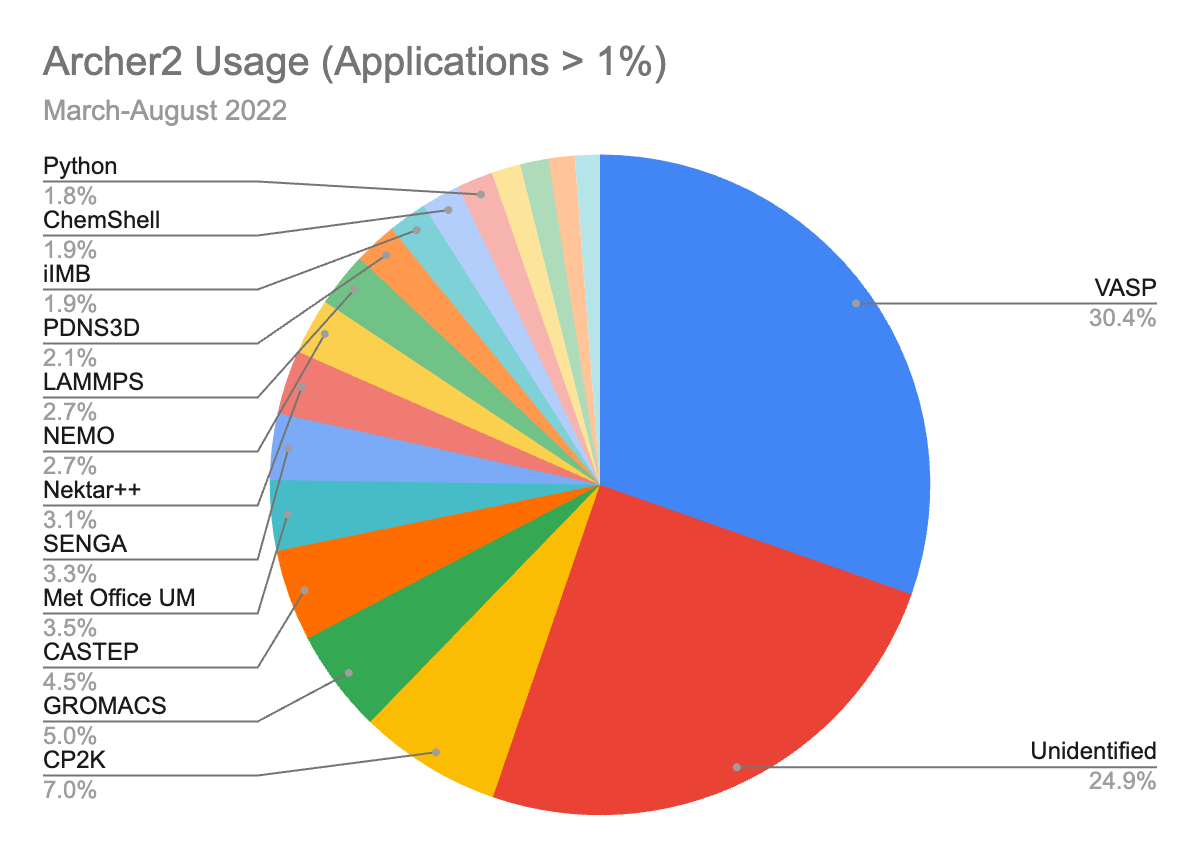
Even at first glance, Fortran seems important, though there’s more to discuss. Graphically that data looks like this:-
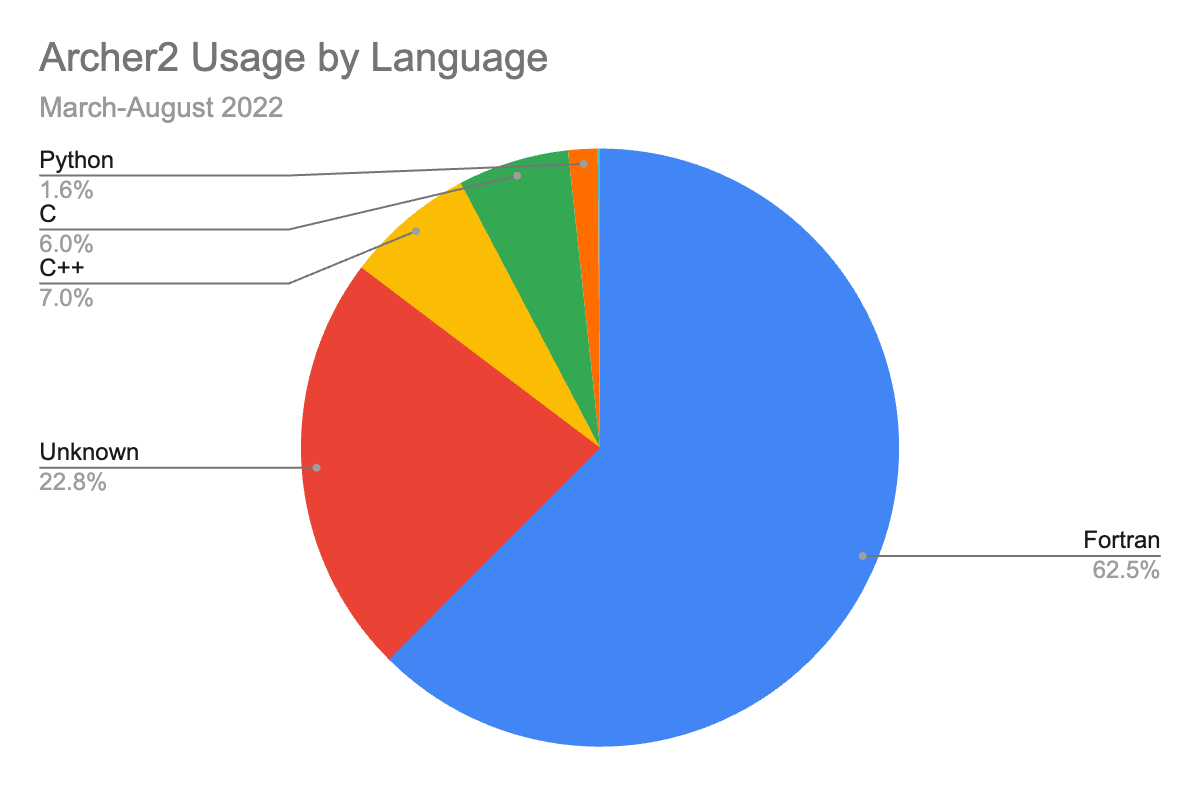
Looking at results for all of the codes, not just the “over 1%” ones, and aggregating by language, we get a view like this :-
What Is That Telling Us?
First, that Fortran is distinctly not pushing up the daisies!
However, we should do a little more analysis and think a bit more about what we mean by saying a code is written in a particular language. In particular, although it is not mentioned in the analysis we can reasonably assume that all the codes on this Linux based computer link against libc, which is written in a mixture of C and assembly code, and that most will be using the dynamic linker, which is also written in C, therefore support for C and assembler is fundamental. However since C is fundamental it can be assumed to be present and someone in a vendor working out what they need to fund to be able to sell an HPC machine doesn’t need to be funding the C compiler. (Heck, Linux wouldn’t be on the machine if it didn’t have a C compiler!)
For that question they need to think about how useful their proposed machine would be, and, therefore, how much of the desired load it could support if they were unable to run codes containing Fortran. From that point of view, we can assign the usage of codes written in Fortran + A.N.Other language to Fortran. If we do that, and (for want of better information) assume that the unknown codes use as much Fortran as those we know about we get these results

So, over 80% of the machine use requires that Fortran is supported.
We can also look at the number of codes written in each language (rather than the compute resources consumed by codes written in it), which shows us that it is not the case that there is just one important Fortran code which is taking all the time while most of the codes are written in other languages. Instead the proportion of codes in each language is similar to the amount of resources consumed.

But Is It Worth Funding the Compiler?
Well, Archer2 is believed to have cost £79 million (~ $102 million at the time)6, of which 81.1% was spent to run Fortran codes, making having such a compiler necessary to enable spending of ~$82.7 million. Or, perhaps more importantly for the CPU vendor, over 9,450 sockets (81.1% of 11,696 total sockets) of high-end, 64 core processors are needed to run Fortran based codes. The Next Platform reckons that the CPUs in those sockets had a list-price of ~$9000, so even with a 50% discount, that is a single sale worth $42.5 million which depends entirely on running Fortran. This is, of course, only one procurement.
Seems worth funding a compiler to me!
Conclusions
Generalising from your personal experience can be misleading. Just because you don’t know any Fortran programmers and don’t write the language yourself doesn’t mean it is unimportant. (I don’t know any long-distance truck drivers, or train drivers, but they definitely exist, and deliver the food and goods I need to survive!)
“Free” software has to be paid for somewhere, and it’s worth thinking a little about how that happens.
If you’re looking for a dead language to mention, maybe use B, BCPL, or Algol, rather than Fortran. That will show that you know a bit more about language history, and aren’t saying something that is provably wrong.
Be careful what you wish for when insulting programming languages; the CTO of Microsoft Azure, Mark Russinovich recently suggested that C and C++ should be deprecated in favour of Rust, so perhaps Fortran will outlive C and C++.
And, the most important one: Fortran is alive and well.
Thanks, Code, etc.
Thanks to the EPCC Archer2 team for making their usage statistics publicly available and to those who rapidly answered my emails asking which language their code is written in.
The script I wrote to aggregate the data (which includes the application to language mapping) and the data files I used are all at in GitHub here. To generate the plots I cut/pasted data from the output of summarise.py into a spreadsheet. (Sorry, I wanted to get this out, and don’t expect to run it often enough to make it worth automating the whole task). Of course anyone who wants to can take that code and enhance it, or just lift the parts they need (like the application name → language dictionary).
The code that EPCC use to generate their statistics (“SLURM Code Usage Analysis” [SCUA]) is all available in GitHub here, and includes their data on application → language mapping (which I have used with one addition).
If anyone is interested in a wider discussion of following the money and growing as a software engineer, the talk I gave (remotely) at UCL back in 2020 may be of interest.
GitHub doesn’t give a language summary for its mirror of the LLVM project. However, running sloccount on a checked out tree gives 67% C++ and 17% C.
You’ll be glad to know that TIOBE excludes searches on “adult” web sites :-) See the definition of their search implementation. So anyone who is searching for C++ pornography (aside from the standard itself) will not be counted.
Since some of those involved in C++ standardisation seem to hate the process (at least judging by their Twitter posts), I can quite understand why they do not also want to pay attention to another ISO standardisation effort!
It will be interesting to see whether the cloud vendors who seem keen to move HPC codes into the cloud will try to differentiate themselves by investing in Fortran compilers and support. It doesn’t seem to have happened yet, but also doesn’t seem completely impossible, particularly once LLVM’s Fortran implementation (LLVM Flang) is a viable basis for tweaks.
The usage data is collected from SLURM, so represents jobs which are submitted to be run at scale. Code which is run on the shared login nodes is not included, but that should mostly be compilation and debugging work, rather than “science runs”.
Good points and interesting figures on the usage of Archer. You caused me to check up a vaguely remembered comment about the future of programming languages - it turns out to be from Tony Hoare (FRS and winner of the 1980 Turing Award) in 1982. He said I don't know what the language of the year 2000 will look like, but I know it will be called Fortran.” It would be a stretch to claim that "The language of the year 2022 is Fortran" but it is certainly the case that what is called Fortran today is not the Fortran I learned in 1972. By the way, the article from 2014 which quoted Hoare makes interesting reading alongside yours - https://arstechnica.com/science/2014/05/scientific-computings-future-can-any-coding-language-top-a-1950s-behemoth/
It was awhile ago, but the Texas Instruments supercomputers, 7 of which were built in the late 1970s were optimized for FORTRAN. To take advantage of that, everything possible including the Cobol compilers were written in FORTRAN.