
Presenting Parallel Performance (1)
Part 1: Do you really want "speedup"?

Introduction
Since parallelism is now an absolute requirement for anything that claims to be a “Super Computer”, we need to present performance results that demonstrate that we are using it effectively as we use more and more of the machine to run our applications. Unfortunately, presenting this scaling data in a useful and not misleading manner is not easy. The (in)famous paper “Twelve Ways to Fool the Masses When Giving Performance Results on Parallel Computers” gives a number of ways of doing the opposite.
Here I am going to discuss speedup curves, which are generally used for showing both inter-node scaling and in-node (shared memory or OpenMP® scaling), while in the following post I’ll dive a bit deeper into the presentation of in-node scaling.
Speedup Curves
There are a number of issues with speedup curves that I’ll run though one by one.
1: Always Beware of Ratios
As David Bailey pointed out, we should always be careful when using any metric which is a ratio, since a ratio give us two ways to make the result go in the direction we want. For instance, if we want to show that our machine is faster than another we might present
Performance Ratio = Performance(our machine)/Performance(competitor)That seems reasonable; if we can improve our performance the number gets bigger. But… we can also make the number bigger by using a poor performance on the bottom of the ratio, and, it’s much easier to make things run slowly than to make them run fast.
An Example
As an example, consider the performance of a trivial benchmark1 (which counts the number of primes below some limit) when compiled by two different compilers. (Here labelled “Compiler A” and “Compiler B”, since the point here is not the numbers, but the way we treat them, so knowing what the compilers are is not necessary). Running on one of the Isambard AArch64 machines, I see performance when counting the number of primes < 10,000,000 like this :-

You can see that on any reasonable view, compiler A is out-performing compiler B, achieving 1.64x performance at -O3.
But… if we were disreputable, and attempting to sell compiler B, we’d look for any way to show that compiler B is faster at something, and, if we compare Compiler B at -O3 with compiler A at -O0, that gives us a performance ratio of 3.233/3.187 = 1.01x, so if we don’t mention how we computed it compiler B is slightly faster. (Or, at least “has similar performance”).
While this specific example is somewhat laboured, it is always important to check where the performance of a competitor’s product has been obtained from when a vendor is making comparisons. Using an old codebase compiled for an old ISA (e.g. compiling for 8087 floating point when benchmarking a 64 bit X86 machine, rather than using any of the many X86 vector FP ISAs) or compiling at -O0 and then comparing with newly revised code compiled with the latest compiler for the newest hardware is certainly not unknown…
Or, comparing parallelised code on one machine with an older, serial, version on another.
As before, making things slow is easy, making them fast is hard.
2: Beware of the Choice of Normalisation
The particular point David Bailey was making is not quite the one above, but, rather that if we are comparing speedups between different systems we need to be very careful about how the normalisation that converts a set of times into a set of speedups is performed. If we compare the simple speedup curves that we’d use when tuning our code on a given machine, the normalisation will be the performance of the single thread/node/… code running on that machine. However, comparing those curves for different machines is highly misleading.2
As an example let’s compare two machines, where machine 2 is twice as fast as machine 1, but generates an induced serial fraction of 20%, whereas machine 1 (the slower machine) achieves a serial fraction of 10%. Using Amdahl’s law we can predict the performance of these two machines.
If we compare the normalised-to-self speedups, we get a graph like this

So, machine 1 is clearly better, right? Its speedup with parallelism of 20 somethings is nearly 7x, whereas machine 2 only achieves slightly over 4x.
But, if we look at the actual time to solve the problem (so smaller is better), we see that although it does not scale as well, machine 2 outperforms machine 1 significantly over this whole range of parallelism which we’re looking at.
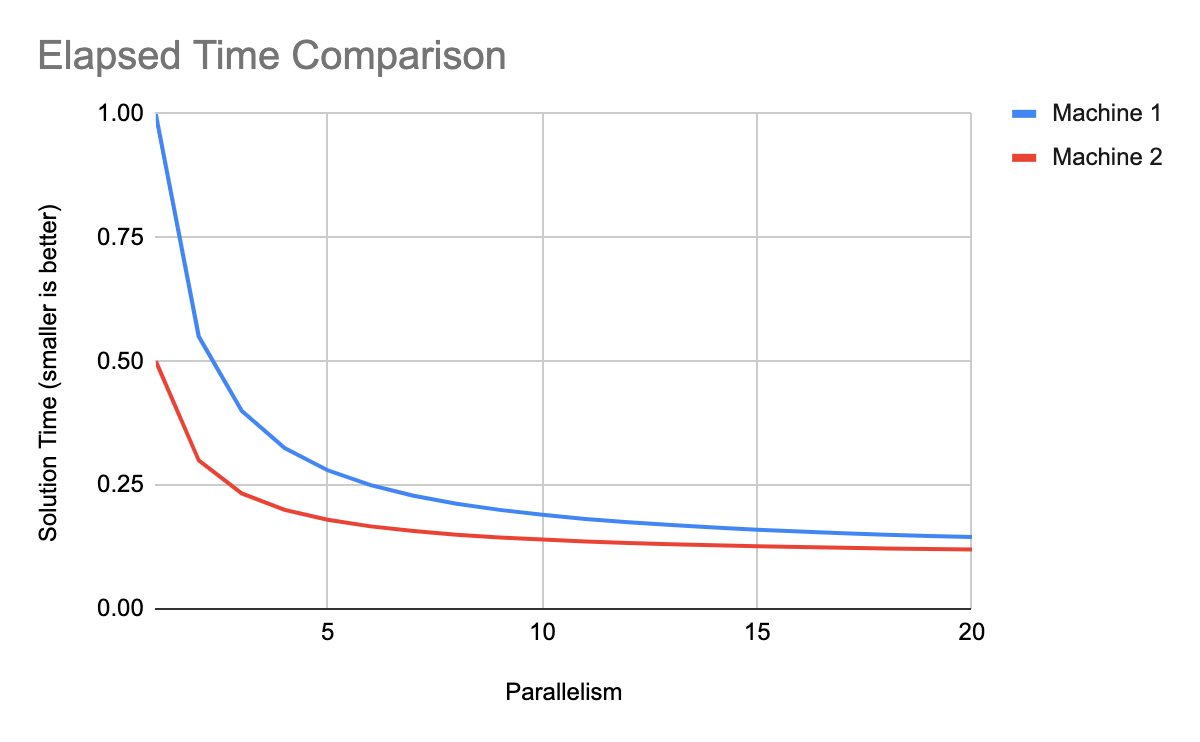
Therefore, if we are going to compare speedup curves from different machines meaningfully, we must ensure that all of the raw performance data is normalised consistently (either to the serial performance of the best machine, or of the worst). When you do that you can see that machine 1 has only half the performance serially, and never catches up in this range of parallelism.

Fundamentally, speedup is not a useful metric for comparing machines; for that it is better to stick to the simpler metric of time, or performance (1/time). This is both simpler to understand and harder to fake.
3: The Graph Itself
The simplest plot (and the one that is easiest to produce) shows the time to solution (or, if you prefer, you can use performance (= 1/time) so that bigger is better). This has many advantages (there are no ratios involved), but it can be hard to see details at both ends of the x-axis. Therefore when investigating the scaling properties of a code on a given machine it is worth also using other plots.
Tufte3 (whom all should read) tells us that we should "maximize the data ink". But, a speedup graph does not meet this rule for three reasons:-
We can be almost certain that half of the area on the graph will not be used. (Everything in the top left of the graph represents super-linear speedup, so rarely contains any data). Therefore that area of the plot is wasted.
To understand how good the scaling is we need a “Perfect Scaling” line on the graph, and have to work out how much worse the data points are than this perfect line. That line is extra ink which is not for the data.
If we present scaling over a large range we can’t see what is going on in thearea where the parallelism is low.
As an example, here is data about the simple question “How well can a relatively small parallel loop in which each iteration takes the same amount of time possibly execute as I change the available parallelism?” Note that this is not a question about how specific schedules (maps of iteration to execution entity [“thread”]) perform, but one about the mathematical fundamentals. When the number of threads does not divide the number of iterations the best any schedule can do is to have an imbalance between the number of iterations executed by any two threads of one iteration, which is what we model here4.
We consider a loop with 50 iterations and look at performance out to 64 threads; assuming each iteration takes 1s, the expected time is like this:-

The Speedup graph then looks like this :-

There is clearly some drop-off even below 10 threads, but it is hard to see exactly what is going on.
OK, So What Should I Plot Instead?
When trying to understand scaling, it is better to plot parallel efficiency (i.e. speedup/parallelism, or, equivalently, the fraction of the available resources which are used) than speedup. The parallel efficiency shows you what proportion of the perfect speedup you are getting, so can be expressed as a percentage. It doesn’t need a “perfect speedup” line, and all levels of parallelism can easily be seen and compared.
Here is the same example presented using parallel efficiency.
Now we can see what is going on both when there are few threads and when there are many. This should match what you expect; you can achieve 100% efficiency only when the number of iterations is divisible by the number of threads. In all other cases there will be some threads which execute one more iteration than others. Clearly the worst case here is when we have 49 threads, since then each thread can execute one iteration, but one thread has to execute two. So 48 threads are idling for half of their execution time, therefore we’d expect (and see) an efficiency of 50/(2*49) ~= 51%.
Of course, this graph is not great for a marketing presentation, since it doesn’t go “up to the right” (and it has each axis labelled, so is definitely not a marketing slide). However for engineering use, and to really understand how our applications scale, this is a better way to present the data5.
What Have We Learned?
Be very careful when looking at metrics which are produced by dividing two values.
Simple plots of time to solution, or performance (1/time), remain the most important graphs for comparing machines or implementations, but when examining scaling performance of a single implementation parallel efficiency beats speedup.
Plots of parallel efficiency allow us to see more detail than speedup curves.
In part 2 we’ll look at another mistake which is easy to make…
Thanks
Roger Shepherd for reading drafts and commenting.
This work used the Isambard UK National Tier-2 HPC Service, operated by GW4 and the UK Met Office, and funded by EPSRC (EP/T022078/1).
The code for this benchmark is available if you really want to run it yourself with different compilers to break the anonymisation.
HIs point is actually slightly stronger even than this, since, as he says, the real comparison should be with the performance of the best available serial implementation rather than the performance of the parallel implementation being run serially.
At the very least you should read “THE VISUAL DISPLAY OF QUANTITATIVE INFORMATION”, but also consider reading his other books.
We also add no overhead for parallelism. If you were attempting to model a real system some such overhead would make sense, but here we’re keeping it simple and showing the fundamental mathematical limit.
Those graph are very difficult to read in dark mode (automatic in the case of the app, because the graph background turns to dark grey and the axis and labels are black and the curve dark blue). Nice article otherwise