
Processing a File with OpenMP®
Simple beats clever.

Introduction
This post is a reaction to a StackOverflow question1, where the poster asked how to create separate parallel teams in OpenMP. However, that was a classic example of “Here’s my bad solution to a problem I haven’t described, please fix this bad solution”, when the real problem they were trying to solve is “How can I stream a file through my code and use line-level parallelism to speed that up?”, which has rather different solutions.
Here we’ll look at the real problem.
The Canonical Problem
Suppose we have a large file and want to perform some operation on each line of the file. Assuming that the operations on each line are independent, there is clearly as much parallelism as there are lines in the file, so it seems that we should be able to speed it up by using a parallel programming environment such as OpenMP.
Concrete Example
As a concrete example we’ll emulate grep -c which counts the number of lines in a file that match a specified regular expression. Given that the C++ standard already includes std::regex the actual processing of the lines is trivial to write, but we can wrap that operation in a variety of different parallel patterns to see which works best. This also has the advantage that we can compare performance with grep to see how we’re doing, and also to check that we’re getting the right answer.
We show the low-level support functions at the very end of this post, so if you want to see how we’re reading data, or what our results structure looks like, dive down there now, whereas if you’re more interested in the parallel meat of this, just keep reading.
Serial Code: “serial”
Given the support functions, our serial implementation really is quite simple
// The obvious, simple, serial code
static fileStats runSerial(std::regex const &matchRE) {
std::string line;
fileStats res;
while (getLine(line)) {
res.incLines();
if (lineMatches(matchRE, line)){
res.incMatchedLines();
}
}
return res;
}We just run over each line, check whether it matches and accumulate the result.
This gives us a simple base from which to experiment with different parallel implementations.
“Classical” OpenMP Implementations
Both of these implementations have multiple threads reading the file, so must serialise those accesses, which is achieved easily using a critical section, like this :-
// Wrap the getLine call in a critical section.
static bool criticalGetLine(std::string & line) {
bool res;
#pragma omp critical (getLineLock)
{
res = getLine(line);
}
return res;
}“parallel”
// A simple parallel version; very similar to the serial one
// except that we have to explicitly serialise reading and
// combining per-thread results.
static fileStats runParallel(std::regex const &matchRE) {
fileStats fullRes;
#pragma omp parallel shared(fullRes, matchRE)
{
std::string line;
fileStats res;
while (criticalGetLine(line)) {
res.incLines();
if (lineMatches(matchRE, line)){
res.incMatchedLines();
}
}
// Accumulate
#pragma omp critical (accumulateRes)
fullRes += res;
}
return fullRes;
}Here we’re wrapping the read operation in a critical section, then each thread is contending for that lock, reading and processing a line before accumulating a local result which, when all the work has been done, is explicitly added back into the global result.
That is fine, and works, but we can make it simpler when we remember that OpenMP has support for user-defined reductions, so we don’t need to implement the reduction ourselves.
User-defined reduction: “parallelRed”
static fileStats runParallelRed(std::regex const &matchRE) {
fileStats res;
#pragma omp declare reduction (+: fileStats: omp_out+=omp_in)
#pragma omp parallel shared(matchRE), reduction(+:res)
{
std::string line;
while (criticalGetLine(line)) {
res.incLines();
if (lineMatches(matchRE, line)){
res.incMatchedLines();
}
}
}
return res;
}This code is even closer to the serial code. We had to introduce the criticalGetLine function and two OpenMP pragmas, but that’s all!
Comparison
Both of these approaches are simple to understand, since all of the threads are executing identical code.
However, as people seem to think it’ll work well, let’s consider using one thread to read lines and all the others to process them.
We’ll start by doing this in an OpenMP sympathetic way, and then move to the less sympathetic “I can write a task queue myself…” style.
“Modern” (i.e. 2008 or later) OpenMP
Tasks: “task”
// Tasks using atomic to update global state.
static fileStats runOmpTasks(std::regex const &matchRE) {
fileStats res;
#pragma omp parallel
{
#pragma omp single nowait
{
std::string * line = new std::string();
while (getLine(*line)) {
res.incLines();
#pragma omp task default(none), \
firstprivate(line),shared(matchRE,res)
{
if (lineMatches(matchRE, *line)) {
res.atomicIncMatchedLines();
}
delete line;
}
} // end task
line = new std::string();
} // while we can read a line
delete line; // Last one isn't passed to a task */
}
} // parallel
return res;
}Here we have one thread reading lines from the source file and creating tasks to do the matching. For simplicity we’re using an atomic operation to update the single, global, shared result. (You might view that as cheating, since if the result was something more complicated than a simple count a critical section would likely be needed…)
Note, though, that there is now explicit management of the std::string which holds the line. We have to allocate and delete it. (At the cost of extra copies we could avoid that, but we are trying to be at least slightly efficient). While we could certainly make that less intrusive (and safer) by using a std::shared_ptr, that doesn’t remove the underlying allocation operations.
This allocation pattern may also invoke a slow path in the heap, since we’re allocating the object in one thread and (almost certainly) releasing it in a different one, so heaps which are optimised for multiple threads by maintaining per-thread allocators might not like this style.
Doing it Ourselves
Writing our own Work Queue: “parallelQ”
We’ve finally got to the solution we were originally asked about, though, even here, we don’t actually need to create multiple OpenMP teams; a “single, nowait” pragma does all that we require if we’re happy to have a single thread do the reading. If we wanted more threads to do it, we could resort to code like this:-
if (omp_get_thread_num() < 3) {
// Code run by three threads
} else {
// Code run by all other threads in the team
}Of course, we’d then need to re-introduce the lock around the reads, avoiding which seemed to be the whole argument for this approach!
For this implementation we need a thread-safe double-ended queue onto which the thread which is reading pushes lines, and from which the other threads pull them.
We can create that by wrapping a std::queue to make it thread-safe.
//
// Something closer to the "I want two separate teams, with one
// thread reading, and others processing lines from a queue."
//
#include <queue>
template<typename T> class lockedQueue {
std::queue<T> theQueue;
bool empty() const {
bool res;
#pragma omp critical (queue)
res = theQueue.empty();
return res;
}
public:
void push(T value) {
#pragma omp critical (queue)
theQueue.push(value);
}
T pull() {
T res;
#pragma omp critical (queue)
{
if (theQueue.empty()) {
res = 0;
} else {
res = theQueue.front();
theQueue.pop();
}
}
return res;
}
};Given that implementation, the code is quite similar to the task example we just showed, though with some added complexity to handle winding down the queue when the file is empty. The problem here is that we have to be careful in the consumers not to assume that because the queue is empty the file is finished, when it may, really, just mean that we’re I/O bound and can’t read lines fast enough.
// One thread reads the lines and adds them to shared queue,
// moving on to processing lines once the file is exhausted.
// Other threads try to pull lines from the queue.
#include <atomic>
static fileStats runParallelQueue(std::regex const &matchRE) {
fileStats res;
lockedQueue<std::string *> lineQueue;
// I find this easier to grok than the OpenMP flush directives!
std::atomic<bool> done(false);
// Use the same reduction operations as before.
#pragma omp declare reduction (+: fileStats : omp_out+=omp_in)
#pragma omp parallel shared(matchRE, lineQueue, done), \
reduction(+:res)
{
#pragma omp single nowait
{
// Read input and produce lines.
std::string * line = new std::string;
while (getLine(*line)) {
lineQueue.push(line);
line = new std::string;
}
done = true;
delete line;
} // single
// Consume lines.
for (;;) {
std::string * line = lineQueue.pull();
if (line) {
res.incLines();
if (lineMatches(matchRE, *line)) {
res.incMatchedLines();
}
delete line;
} else if (done) {
break;
}
}
}
return res;
}Note the use of std::atomic<bool> for the done flag which we use for inter-thread communication. You can certainly argue that I should be sticking entirely to OpenMP features, however I find this simpler than trying to be confident about OpenMP flush directives2!
How do they Compare?
Understandability
From a legibility and similarity to the serial code point of view, the ParallelRed code is the clear winner. The logic remains the same as the serial code, and the changes required are small.
The worst code here is the ParallelQ. It has a lot of support code and the logic has changed significantly, as there is complexity here (such as knowing when to finish) which wasn’t present in the serial, or other parallel, codes. This code also has what you might well consider a bug: think about what happens when it is run with a single thread? When is the scanning of each line done?
The task code is in the middle. It’s relatively easy to understand, but still has the problem that different threads are executing different code-paths, which makes reasoning about it harder. Although it has different threads executing different code paths it should work fine with one thread, since OpenMP semantics allow the runtime to execute a task immediately in the creating thread, which is something it clearly should do when there is only one thread.
Performance
To test this, I ran with 1, 2, 4, 6 or 8 threads on a Marvell/Cavium TX2 node in the Isambard3 machine. (Full configuration details are at the end of the blog).
The input file is generated by the generateText.py script, and contains 500,000 lines, each 50 characters (+ ‘\n’) long (i.e. the file is 25.5MB bytes big). We search for the regular expression “[aA].*[eE].*[iI].*[oO].*[uU]” (which is not utterly trivial).
Time is measured by /usr/bin/time -p, so reflects the elapsed, wall-clock time to execute the code, and the input file is read from stdin via a shell redirection from the real file (both here and for grep -c). Each experiment is run ten times, and we show the arithmetic mean and standard deviation.
The code was compiled with clang++.
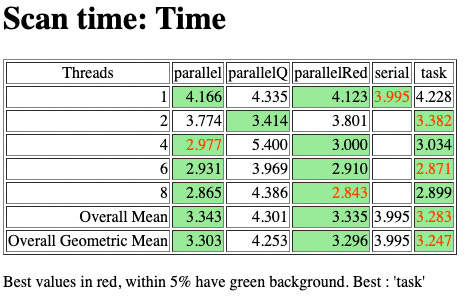
After all of which… here are the results for the elapsed time graphically :-

Our serial implementation took, 3.995s, so is marginally faster than any of the parallel ones when they are running with a single thread.
We can see that none of our implementations is scaling well, and that the simpler implementations all perform significantly better than the more complicated user-implemented queue!
If we want to reduce the results to a single number, we can take the geometric mean of the results at each thread count, which shows that the tasking implementation is marginally the best, followed by the parallel reduction implementation which is only a few percent slower. (3.296/3.247 ~= 1.015).
But, What About grep?
After all of that effort, how are we doing relative to grep? We’ve got to be way faster, right!?
Well, actually, no. grep -c takes 0.06s, which is 47x faster than our best result! Plus it is only using a single thread, so the total CPU time consumed is approximately the same as the elapsed time.
So, This Was All A Waste of Time?
I hope not!
What I take away from this is :-
Before worrying about parallelism it is important to profile and see what the real rate-limiting factors in a code are. For this example it seems that the input processing is the main limit, and that we should be worrying about that (and the associated memory management) before reaching for parallelism. The fact that our serial code is ~66x slower than
grepis definitely the first issue to address even though we’re on a 64 core (256 thread) machine.Once we do get to parallelism, the simple, natural, OpenMP approaches beat trying to take complete control ourselves.
You do not need multiple teams, or to use the
num_threadsclause. Usingnum_threadsis equivalent to making these statements about your code:This code is so unimportant that
I’ll only run it on one machine.
I’ll throw it away before I upgrade my machine.
No-one else will ever use it.
Which seem a depressing set of criteria for any code!
Full Code & Support Functions
The whole code is available in the CPU-fun github if you want to play with it. There are also a few more parallel implementations there, which weren’t worth discussing. The graph and table are produced by the scripts/plot.py4 script from the Little OpenMP (lomp) runtime code, which will digest the output from the benchmark if you use runscan.py to run them.
For completeness, here are the simple functions and classes we use. First, reading a line from stdin.
// Using std::string is unlikely to be the fastest way to
// handle this, since it leads to lots of memory
// allocation/deallocation.
// Better would be to allocate big chunks of memory (or,
// simply mmap the whole file), and slice it up into lines
// referenced by pointers to start/end.
// But, this is simple.
static bool getLine(std::string &line) {
std::getline(std::cin, line);
return !std::cin.eof();
}Matching a line using std::regex.
// See https://en.cppreference.com/w/cpp/regex for details
// of how to use the std::regex class.
static bool lineMatches(std::regex const re,
std::string & line) {
return std::regex_search(line, re);
}and the class we use to accumulate the results
// A class to handle our results.
class fileStats {
int lines;
int matchedLines;
public:
fileStats() : lines(0), matchedLines(0) {}
void zero() { lines=0; matchedLines=0; }
int getLines() const { return lines; }
int getMatchedLines() const { return matchedLines; }
void incLines() { lines++; }
void incMatchedLines() { matchedLines++; }
void atomicIncMatchedLines() {
#pragma omp atomic
matchedLines++;
}
fileStats & operator+=(fileStats const & other) {
lines += other.lines;
matchedLines += other.matchedLines;
return *this;
}
void criticalAdd(fileStats & other) {
#pragma omp critical (addStats)
*this += other;
}
};Benchmark Environment
Machine: GW4 Isambard "XCI" - Cray XC50 Arm/ThunderX2
lscpu:
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 256
On-line CPU(s) list: 0-255
Thread(s) per core: 4
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Model: 2
BogoMIPS: 400.00
NUMA node0 CPU(s): 0-31,64-95,128-159,192-223
NUMA node1 CPU(s): 32-63,96-127,160-191,224-255
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics cpuid asimdrdmuname -a: Linux xcil01 4.12.14-150.17_5.0.90-cray_ari_s #1 SMP Tue Apr 28 21:17:03 UTC 2020 (3e6e478) aarch64 aarch64 aarch64 GNU/Linux. clang++ --version: clang version 11.0.0 (https://github.com/llvm/llvm-project.git 176249bd6732a8044d457092ed932768724a6f06)Compilation flags: -O3 -fopenmp
I am intentionally not giving the link. With good Google-fu I am sure you can find it yourselves if you really want to.
Note that the OpenMP standard itself says in a note “Synchronization through variables is possible but is not recommended because the proper timing of flushes is difficult.”
This work used the Isambard 2 UK National Tier-2 HPC Service (http://gw4.ac.uk/isambard/) operated by GW4 and the UK Met Office, and funded by EPSRC (EP/T022078/1)
Thank you, for the article. It inspired me to try OpenMP and memory mapping using the fast_io C++ library. See complementary solutions; grep-count (using std::regex) and grep-count-re2 (using RE2). https://gist.github.com/marioroy/b06e741bd2685fae3c1fea94808bd1e3
I was reminded of https://adamdrake.com/command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html